Systems Design: 01 nREPL clojure
Meta:
This blog post is based on commit: https://github.com/nrepl/nrepl/commit/21a3200a5dee737efa0dca7529cd2b69b41c7644 This the 2nd entry of unconventional systems design.
nREPL
The nREPL consist of different (github) repositories: the nREPL server, the clients and middleware extensions.
The “unconventional map” I draw for nREPL it should give most of the key ponts to understand nREPL general architecture. It doesn’t cover all the details and I think one could draw different maps for the specifics components interactions which will go more in details. If you feel the motivation to continue it for nREPL feel to fork this and continue it! :)
For me was a great occasion to learn and gain new general insights.
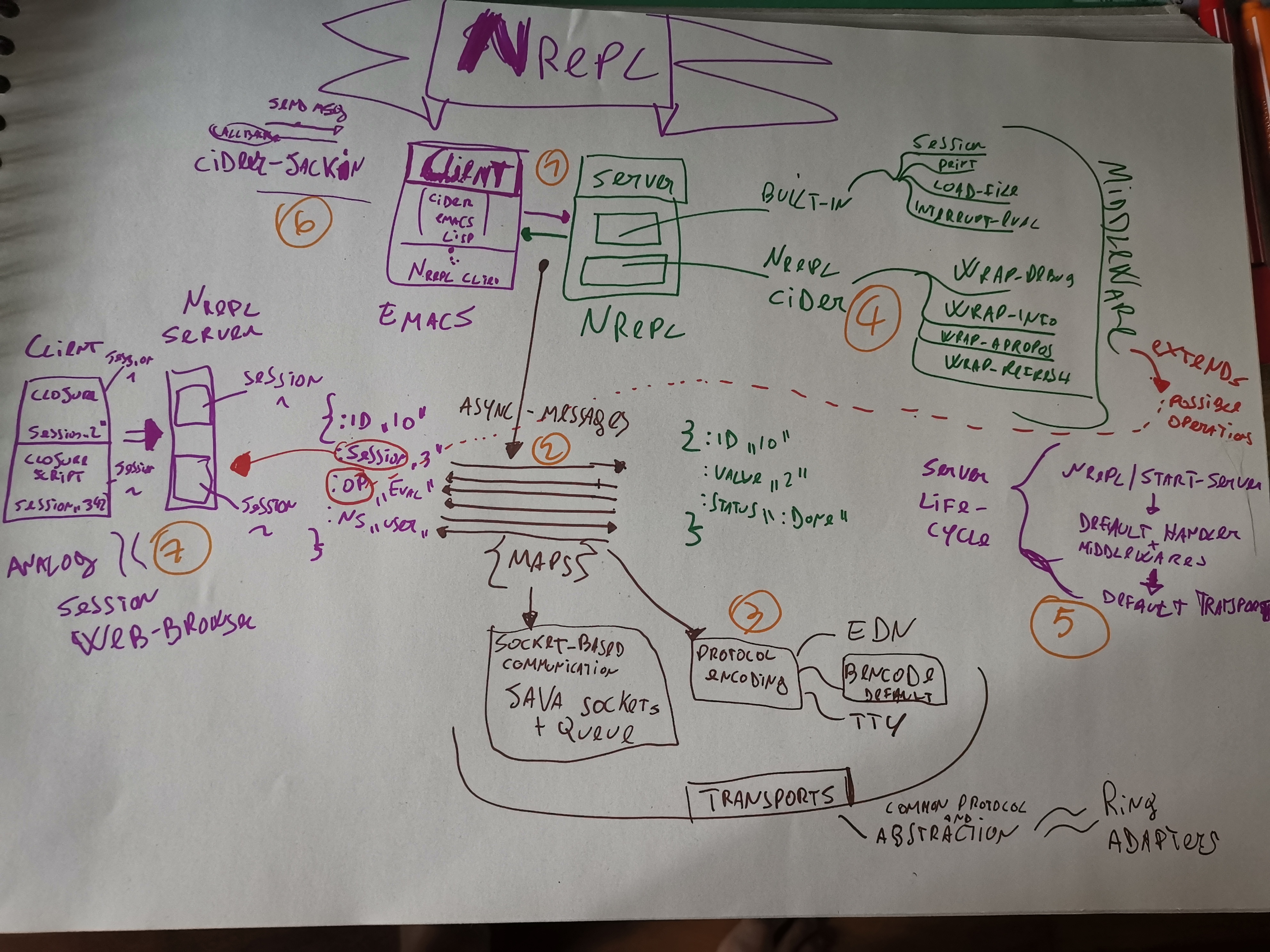
We can structure the picture in 7 key points:
- 1) The architecture model of nREPL
- 2) How data flows in nREPL
- 3) The Transport abstraction
- 4) What is a nREPL server
- 5) A nREPL Server Lifecycle
- 6) A Client of nREPL
- 7) What is nREPL session
TIP: For each point in the list, I will suggest you to look at the map first, then read the description and finally relook the map with the new informations.
1) The architecture model of nREPL
nREPL use a server/client model. We use emacs as client but it could be another client. (see other clients here: https://nrepl.org/nrepl/usage/clients.html)
The highlevel definition from nREPL from upstream doc:
nREPL is a Clojure network REPL that provides a REPL server and client, along with some common APIs of use to IDEs and other tools that may need to evaluate Clojure code in remote environments.
For people not familiar with REPL read here
2) How data flows in nREPL:
nREPL is message-oriented and asynchronous system.
A message consist of a “clojure” map. The real format of this map is abstracted by the transport, which we will see later.
The client on the picture(left side) is sending a message with ID 10 to the server, for “evaluating” “eval” some code. (The example in the picture is simplified)
When you evaluate some code with your editor, e.g CIDER-EMACS sends to the NREPL server a message; the server respond with the value and a “status” of the operations.
We will analyze more in details the specification of map, especially “op” operation field and the “session” field of the maps. ( see red color on the picture).
3) Transport abstraction:
The transport is a common abstraction for providing some facility over the network layer.
Nrepl uses Java sockets. For encoding/decoding the message it uses by default the BENCODE format, but other are supperted.(For more info read this: https://nrepl.org/nrepl/design/transports.html)
The transport namespace is what you will use/require when you develop a new custom middleware for nREPL. The transport are analog to RING adapters, https://github.com/ring-clojure/ring/wiki
CODE is here: https://github.com/nrepl/nrepl/blob/master/src/clojure/nrepl/transport.clj
4) What is a nREPL server:
Everthing in nREPL is message driven and an important part of the message is the “op” keyword of messages.
The “op” correspond to the operations that a client request the nREPL server to perform. It can be “eval” for evaluationg code, “interrupt” for interrupting a task, “load-file”, etc. This all operation requested by your IDE client when you are using the REPL (e.g with CIDER or CALVA). If you require a new operation, you can extend it with middlewares.
The middlewares provide a mechanism to react to specific message operations.
A nREPL server by default provide some basic functionality (built-in middlewares), like session, load-file etc. (see here for more details https://github.com/nrepl/nrepl/tree/master/src/clojure/nrepl/middleware and this are supported by the default-handler )
A nREPL server can be extended, in our case we are using cider-nrepl (https://github.com/clojure-emacs/cider-nrepl), but when using other clients one could/need to extend it with additional middlwares. (refer to: https://github.com/nrepl/nrepl/wiki/Extensions#middlewares)
A middleware allow developer to extend nREPL basic functionality. You can read more here: https://nrepl.org/nrepl/design/middleware.html
5) nRepl Server lifecycle:
nREPL server by start loads the configuration and all the default built-in middlewares plus the customs one (e.g the cider), and initialize the socket-based nREPL server with BENCODE as default.
After server init, it basic wait for incoming messages from clients. ( In details there are some other operation but abstracting this).
You could have look at: https://github.com/nrepl/nrepl/blob/master/src/clojure/nrepl/server.clj
6) a Client of nREPL
Cider is a client for nREPL: it extend emacs for allowing the interactive development for clojure. https://docs.cider.mx/cider/index.html
Emacs-cider https://github.com/clojure-emacs/cider sends message to nREPL server and perform callbacks when the message from server are back.
When createing a new nREPL client, you need to develop 2 parts: one part will be on your IDE/Editor and the 2nd part need to be a middleware for nREPL.
7) Session of nREPL:
Session is a concept analog to the web-browser session
From Upstream doc:
Sessions are for tracking remote state. They’re fundamental to allowing simultaneous activities in the same nREPL. For instance - if you want to evaluate two expressions simultaneously you’ll have to do this in separate session, as all requests within the same session are serialized.
If you use Clojure and Clojurescript, Piggieback uses sessions to allow host a ClojureScript REPL alongside an existing Clojure one.
Conclusion:
I have just drawed an essential view of nREPL; some infos are also simplified for not going into much complexity.
Thx to @bbatsov for answering some questions, thx to all contributors and maintainers for providing a great design and developer documentation to work with.